OOMKilled
Table of contents
Cluster
OOM Killed 상태란?
pod에 리소스(메모리/CPU) 제한을 설정한뒤에 컨테이너가 허용된 것보다 많은 리소스 할당하려고 하면 오류가 발생합니다. 일반적으로 이 경우 컨테이너가 죽고 kubernetes는 해당 pod를 재시작 합니다.
일반적인 장애 증상
- 문제가 되는 Pod가 OOMKilled 이벤트 받으면서 지속적으로 재기동 됨
문제확인 방법
- Pod 상태 확인
메뉴 → 워크로드 -> Pod
scouter-server-68bc9b95f6-smfhp 2/2 Running 218 14d scouter-server-68bc9b95f6-smfhp 1/2 OOMKilled 218 14d scouter-server-68bc9b95f6-smfhp 1/2 NotReady 219 14d - Pod 자원 모니터링
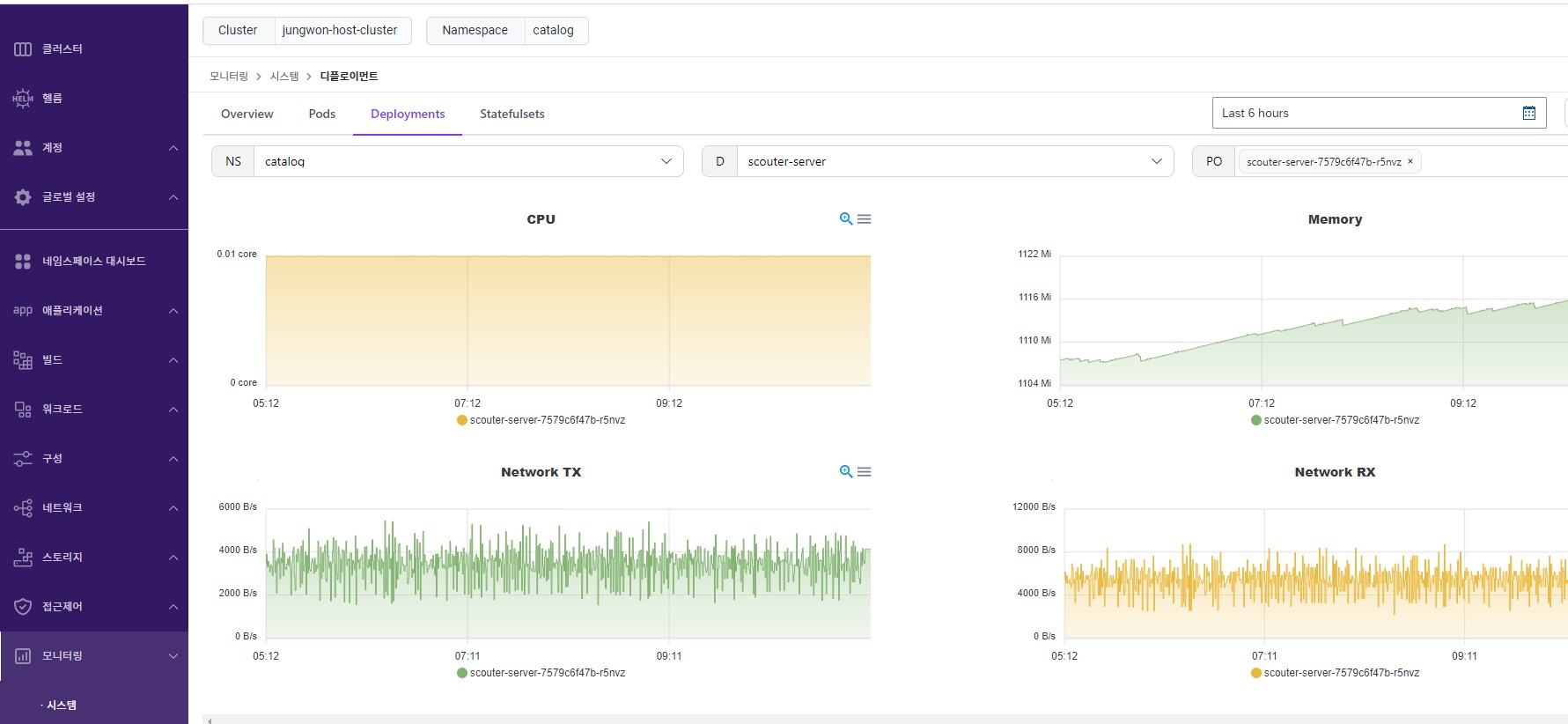
메뉴 -> 모니터링 -> 시스템
[root@jwkim-master ~]# kubectl top pod -n catalog NAME CPU(cores) MEMORY(bytes) ac2-843-8447f9f8c4-dh8kc 0m 5Mi acc-redis-5c67456577-bkvn4 2m 21Mi ha-02-75999df5ff-j5dp8 1m 367Mi nginx-5d6c7cdff5-qwk4b 0m 6Mi nginx-test-03-d5f78f6fc-sfcwg 0m 9Mi trivy-rules-57b5bfc684-nmgmj 1m 26Mi war-2pod-8579c8ccfc-9ftjn 5m 430Mi wildlfy-ha-77ddd8cc44-njgs8 7m 747Mi wildlfy-ha-77ddd8cc44-plqts 7m 745Mi - kubelet 로그 확인
$ grep -i OOM messages
Mar 15 09:22:41 acc-jejupass03 containerd: time="2022-03-15T09:22:41.553168162+09:00" level=info msg="TaskOOM event &TaskOOM{ContainerID:0527c6dd14e504ab8c406806e0ce182aec604a0dbeeefc4e94e1ee3550dda3db,XXX_unrecognized:[],}"
Mar 15 09:22:41 acc-jejupass03 kernel: VM Thread invoked oom-killer: gfp_mask=0xd0, order=0, oom_score_adj=984
Mar 15 09:22:41 acc-jejupass03 kernel: [<ffffffffaadbfd74>] oom_kill_process+0x254/0x3e0
Mar 15 09:22:41 acc-jejupass03 kernel: [<ffffffffaae3c666>] mem_cgroup_oom_synchronize+0x546/0x570
Mar 15 09:22:41 acc-jejupass03 kernel: [ pid ] uid tgid total_vm rss nr_ptes swapents oom_score_adj name
Mar 15 09:22:41 acc-xxxxx containerd: time="2022-03-15T09:22:41.563701093+09:00" level=info msg="TaskOOM event &TaskOOM{ContainerID:0527c6dd14e504ab8c406806e0ce182aec604a0dbeeefc4e94e1ee3550dda3db,XXX_unrecognized:[],}"
Mar 15 09:22:41 acc-jejupass03 kernel: VM Thread invoked oom-killer: gfp_mask=0xd0, order=0, oom_score_adj=984
Mar 15 09:22:41 acc-jejupass03 kernel: [<ffffffffaadbfd74>] oom_kill_process+0x254/0x3e0
Mar 15 09:22:41 acc-jejupass03 kernel: [<ffffffffaae3c666>] mem_cgroup_oom_synchronize+0x546/0x570
Mar 15 09:22:41 acc-jejupass03 kernel: [ pid ] uid tgid total_vm rss nr_ptes swapents oom_score_adj nam
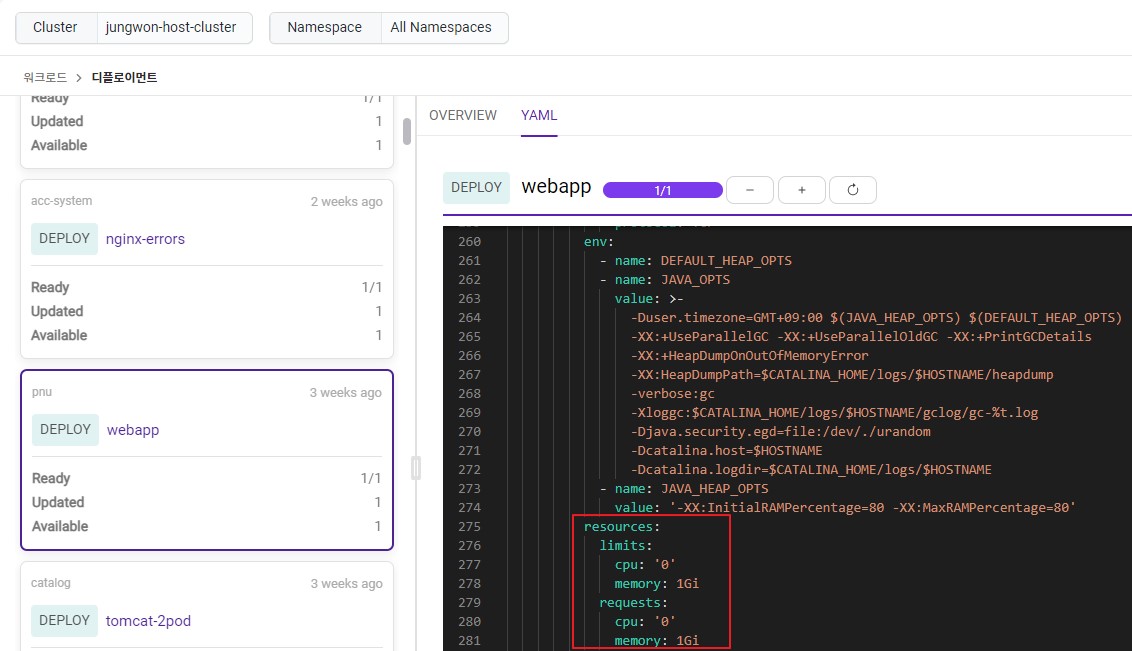
조치 방법
트래픽 분석 후 애플리케이션에서 리소스가 부족하다면 리소스 쿼터 조정하여 리소스 증설
$ kubectl edit deployment <deployment> -n <namespace>
리소스가 예기치 않게 스파이크 처서 애플리케이션에 접속되지 않는 경우 프로그램에서 리소스 leak이 발생하고 있을 가능성이 있으므로 프로그램을 디버깅하여 원인을 찾아야 함- 메모리 점차 증가 확인
[root@jwkim-master ~]# while true do sleep 1 free -h done used buff cach free 12.2G 688k 3378M 190M 12.4G 644k 3175M 183M 12.5G 560k 3012M 180M 12.6G 408k 2888M 233M 12.7G 284k 2813M 242M 12.9G 160k 2584M 216M 13.1G 28.0k 2352M 231M 13.2G 16.0k 2335M 207M 13.2G 16.0k 2303M 238M 13.2G 12.0k 2254M 257M 13.2G 8192B 2232M 287M 13.2G 8192B 2285M 228M 13.2G 4096B 2254M 271M 13.2G 4096B 2268M 253M 13.2G 4096B 2250M 269M 13.2G 4096B 2281M 243M 13.2G 4096B 2311M 211M- 컨테이너 리소스 확인
CONTAINER CPU % MEM DISK INODES b571874ae948f 0.13 13.56MB 0B 0 b571874ae948f 0.06 13.63MB 0B 0 b571874ae948f 0.13 13.91MB 53.25kB 16 571874ae948f 100.24 3.236GB 1.622GB 21833 b571874ae948f 69.57 3.569GB 2.048GB 21833 b571874ae948f 74.42 3.569GB 2.048GB 21833 b571874ae948f 0.04 3.569GB 2.048GB 21833 b571874ae948f 0.00 3.569GB 2.048GB 21833 b571874ae948f 0.02 3.569GB 2.048GB 21833- b571874ae948f 컨테이너는 kaniko 이미지로 컨테이너 빌드하는 애플리케이션
- kaniko에서 compressed-caching=false 옵션 사용 시 메모리 누락 발생
- 이슈 확인 https://github.com/GoogleContainerTools/kaniko/issues/1680
- 패치 확인 https://github.com/GoogleContainerTools/kaniko/releases)